PDF OCR X
Version: 3.0.34
Demo
Convert PDFs into text documents.




Version: 3.0.34
Demo
Convert PDFs into text documents.
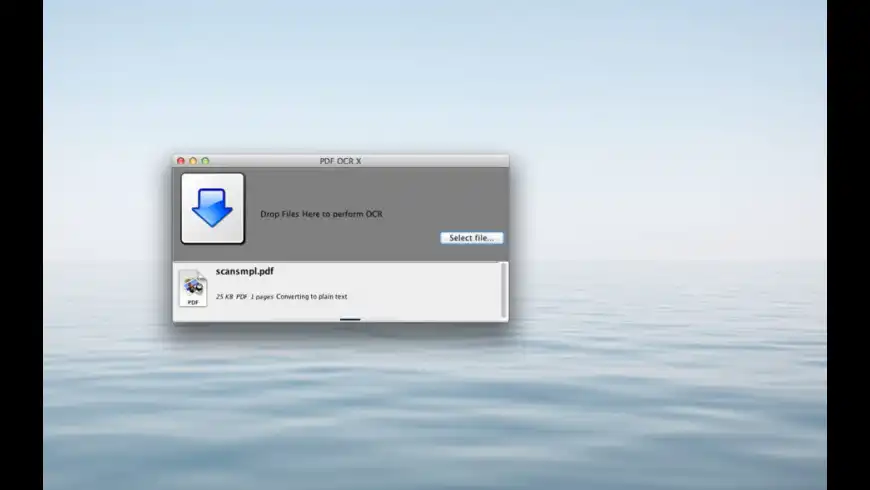
PDF OCR X is a simple drag-and-drop utility that converts your PDFs into text or searchable PDF documents. It uses advanced OCR (optical character recognition) technology to extract the text of the PDF even if that text is contained in an image. This is particularly useful for dealing with PDFs that were created via a Scan-to-PDF function in a scanner or photocopier. Supports over 60 languages including English, French, German, Dutch, Spanish, Portuguese, Basque, Vietnamese, and Italian currently. The OCR engine is based on Tesseract.
Note: The free community edition is limited to PDFs of 1 page or less. The Enterprise version ($29.99) has no limit on the size of the PDF.
License
Demo
Size
57.7 MB
Downloads
Demo
Developer's website
https://solutions.weblite.ca/pdfocrx/
App requirements